python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python ...
”python 爬虫 后端 学习 scrapy“ 的搜索结果
scrapypython爬虫学习 scrapy框架 爬虫学习python爬虫学习 scrapy框架 爬虫学习python爬虫学习 scrapy框架 爬虫学习python爬虫学习 scrapy框架 爬虫学习 scrapypython爬虫学习 scrapy框架 爬虫学习python爬虫学习 ...
Scrapy是一个用Python编写的快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从中提取结构化的数据。:Scrapy提供了清晰的API和灵活的爬虫设计,使得代码易于理解和维护。:它允许用户通过自定义的中间件和...
(1)什么是下载中间件:下载中间件是一个用来hooks(钩子)进Scrapy的request/response处理过程的框架。它是一个轻量级的底层系统,用来全局修改scrapy的request和response。scrapy框架中的下载中间件,是实现了...


首先知识点和方向实在是太多了,它关系到了计算机网络、编程基础、前端开发、后端开发、App 开发与逆向、网络安全、数据库、运维、机器学习、数据分析等各个方向的内容,它像一张大网一样把现在一些主流的技术栈都...
首先知识点和方向实在是太多了,它关系到了计算机网络、编程基础、前端开发、后端开发、App 开发与逆向、网络安全、数据库、运维、机器学习、数据分析等各个方向的内容,它像一张大网一样把现在一些主流的技术栈都...

Python爬虫5.2 — scrapy框架pipeline模块的使用综述pipeline核心方法process_item(item, spider)close_spider(spider)close_spider(spider)from_crawler(cls, crawler)使用pipeline一个spider多个item类型结构情况...
在本篇博客中,我们首先介绍了...然后,我们介绍了Scrapy框架,这是一个强大的Python爬虫框架,提供了完整的爬虫解决方案。我们学习了如何创建一个新的Scrapy项目、创建一个爬虫、编写爬虫代码、解析数据和存储数据。
爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。这个定义看起来很生硬,我们换一种更好理解的解释:我们作为用户获取网络数据的方式是浏览器提交请求->下载网页代码->解析/渲染成页面;而爬虫的...
但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy 是基于twisted...
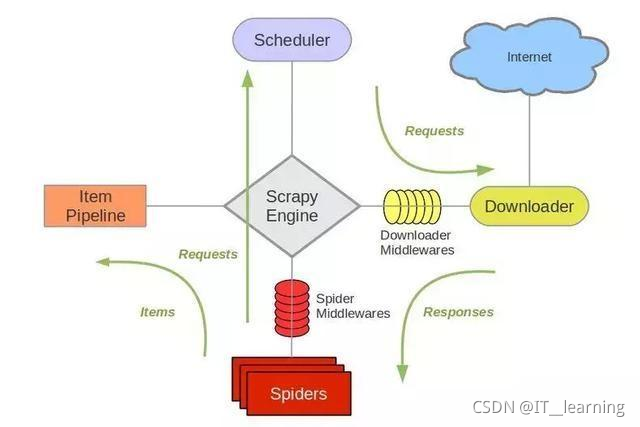
文章目录Scrapy 框架一、 简介1、 介绍2、 环境配置3、 常用命令4、 运行原理4.1 流程图4.2 部件简介4.3 运行流程二、 创建项目1、 修改配置2、 创建一个项目3、 定义数据4、 编写并提取数据5、 存储数据6、 运行...
首先知识点和方向实在是太多了,它关系到了计算机网络、编程基础、前端开发、后端开发、App 开发与逆向、网络安全、数据库、运维、机器学习、数据分析等各个方向的内容,它像一张大网一样把现在一些主流的技术栈都...
我当时就把百度百科的词条作为节点,词条的一些其他内容作为节点属性,节点之间的关系...- spider:爬虫文件,使用的是Scrapy框架,主要作用就是爬取百度百科中有关制造业的词条,形成用于展示的知识图谱的节点和关系。
有没有大神分享一个纯python无框架写的webapi后端...python自学完了,想写个api练练手,CSS布局HTML小编今天和大家分享个案例代码来借鉴借鉴精华你可能有误解,无框架要比使用框架复杂的多。 你刚学完,应该是先试试...
Python Scrapy 爬虫框架整个学习demo,包括后端数据库等逻辑的一些代码
大数据毕业设计Python+SpringBoot+Scrapy制造业知识图谱可视化 智能制造知识工程平台 机器学习 neo4j 大数据毕设 计算机毕业设计 机器学习 深度学习 人工智能
爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。这个定义看起来很生硬,我们换一种更好理解的解释:我们作为用户获取网络数据的方式是浏览器提交请求->下载网页代码->解析/渲染成页面;而爬虫的...
本项目结合自身所学,后端采用Python的flask框架,结合scrapy爬虫,前端使用React,再结合Elasticsearch的基础功能用于搜索,然后用Docker容器部署到服务器。 ## 部署 -------- 该资源内项目源码是个人的毕设,代码都...
然后在命令行运行scrapy crawl spider,一旦关闭远程连接,爬虫就会停止,很不爽,毕竟能让一个爬虫在服务器一直跑才是每个小白的梦想= =,所以开始研究如何使程序在后台运行,刚开始看了scrapyd,感觉不好用,又搜...
想要学习Python?有问题得不到第一时间解决?来看看这里,满足你的需求,资料都已经上传至文件中,可以自行下载!还有海量最新2020python学习资料。 点击查看 【问题发现】 爬虫项目中,为了防止被封号(提供的可用...
Python爬虫是用Python编程语言实现的网络爬虫,主要用于网络数据的抓取和处理,相比于其他语言,Python是一门非常适合开发网络爬虫的编程语言,大量内置...(推荐学习:Python视频教程) Python爬虫架构组成1. URL管理...
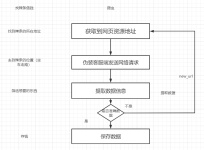
原来已经用Python开发了新闻网站项目,这个项目进行了2次开发,加入基于Scrapy框架爬取网易新闻数据,爬取到的数据保存到mysql数据库里面,然后采用python后端语言进行各种数据分析,将分析的结果在前端用echarts...
本文将介绍如何以优雅的方式进行Python爬虫后端开发,并提供相应的源代码示例。在开始爬虫后端开发之前,首先需要明确爬取的目标。确定要爬取的网站、所需的数据类型以及数据获取的方式。这有助于我们设计合适的爬虫...
随后,我们采用Python后端语言,对这些数据进行深入而全面的分析,挖掘出隐藏在数据背后的有价值信息。为了将这些分析结果直观地呈现出来,我们利用了前端echarts图表技术,打造了一个可视化大屏展示系统,使得数据...
本项目爬虫端和网站后台采用Python语言开发,其中爬虫利用的是Scrapy框架可以轻松实现网站数据的抓取,抓取到的兼职信息直接保存到mysql数据库中,前端采用Vue开发,实现了前后端分离的模式,前端请求Django后端接受...
推荐文章
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地
- Python 攻克移动开发失败!_beeware-程序员宅基地
- Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
- 元素三大等待-程序员宅基地
- Java软件工程师职位分析_java岗位分析-程序员宅基地
- Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
- 标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地